지능형 에이전트 (Intelligent Agents)
- 인공지능 접근 방법론으로 합리적 에이전트 (Rational Agents) 개념을 사용한다.
- cf)
| |
생각 |
동작 |
| 인간처럼 |
인지과학 |
튜링 테스트 |
| 합리적 |
논리학 |
에이전트 |
✅ 에이전트 (Agent) 란?
센서를 통해 주변 환경을 지각하고 동작 기관을 통해 동작하는 모든 것

환경의 속성 (Properties of Environments)
✅완전 관측 가능 (Fully Observable) vs. 부분 관측 가능 (Partially Observable)
각 시점에서 에이전트 센서가 주변 환경의 완전한 상태에 접근 가능한지 여부에 따라 구분
- 완전 관측 가능 - 체스 게임에서 Agent, 즉 Player는 상대 말의 위치를 전부 관측할 수 있다.
- 부분 관측 가능 - Texas Holdem Poker에서 Agent, 즉 Player는 상대 카드의 정보를 알 수 없다.
✅단일 에이전트 (Single-Agent) vs. 다중 에이전트 (Multi-Agent)
몇 개의 에이전트가 존재하는지에 따라 구분
- 단일 에이전트 - 십자말풀이의 경우, Player가 한 명이다.
- 다중 에이전트 - 체스 게임의 경우, Playre가 두 명이다.
✅결정적 (Deterministic) vs. 비결정적 (Nondeterministic - Stochastic)
주변 환경의 다음 상태가 완전히 결정되어 있는지 여부에 따라 구분
- 결정적 - 체스 게임에서 말을 앞으로 한 칸 옮기고자 한다면 다음 상태는 100% 결정적이다.
- 비결정적(확률적) - Texas Holdem Poker에서 카드를 확인한다고 해도 어떤 카드가 나올지는 모른다. 즉, 확률적이다.
✅단편적 (Episodic) vs. 순차적 (Sequential)
다음에 할 동작이 이전 상태에 영향을 미치는지 여부에 따라 구분
- 단편적 - 단편적 환경에서는 다음에 할 동작이 이전 상태에 비종속적이다.
- ex) 이미지 분류를 할 때, 이전 사진에 대한 분류가 이후 사진 분류에 전혀 영향을 미치지 않고 독립적인 episode로 작용한다.
- 순차적 - 순차적 환경에서는 다음에 할 동작이 이전 상태에 종속적이다.
- ex) 체스 게임의 경우 현재의 선택이 이후 상황에 영향을 미치는 종속적인 episode로 작용한다.
✅정적 (Static) vs. 동적 (Dynamic)
에이전트가 다음 동작을 고민하는 동안 주변 환경이 변하는지 여부에 따라 구분
- 정적 - 십자말풀이를 하는 동안 문제나 환경이 변화하지 않는다.
- 동적 - 자동차를 운전하는 동안 도로 상황은 끊임없이 변화한다.
✅이산적 (Discrete) vs. 연속적 (Continuous)
환경의 상태, 시간의 처리 방식, 에이전트의 지각과 동작의 형태에 따라 구분
- 이산적 - 체스 게임의 경우 나의 턴과 상대의 턴을 나누어 시간을 이산적으로 소비한다.
- 연속적 - 자동차 운전의 경우 실시간으로 끊임없이 변화하는 환경 속에서 시시각각 운전을 수행한다.
에이전트의 4가지 종류 (Four Kinds of Agents)
- 인공지능의 목표는 에이전트 함수를 수행하는 에이전트 프로그램을 구현하는 것이다.
- "센서를 통해 얻은 지각을 어떻게 동작으로 옮기는가"
- 인공지능의 중요 과제는 합리적인 동작을 수행하는 프로그램을 찾는 것이다.
✅ 단순 반응형 (Simple Reflex Agents)
- 가장 단순한 형태의 에이전트
- 과거 지각은 무시하고, 항상 현재 지각에만 근거하여 동작을 선택한다.
- ex) 진공 청소기 에이전트
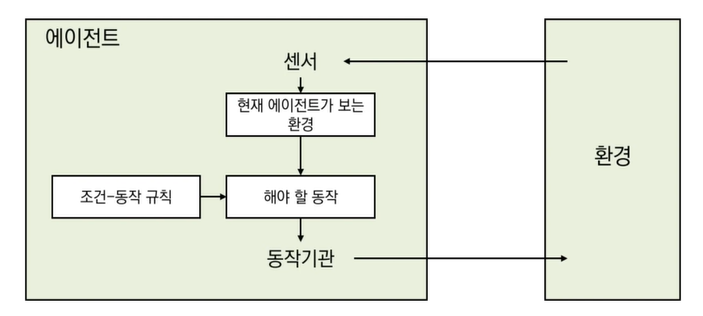 단순 반응형 에이전트
단순 반응형 에이전트
✅ 모델 기반 반응형 (Model-Based Reflex Agents)
- 과거의 지각들에 대한 기억을 저장하는 내부 상태를 유지한다.
- 즉, 과거에 대한 기억들이 현재의 동작에 영향을 미친다.
 모델 기반 반응형 에이전트
모델 기반 반응형 에이전트
✅ 목표 기반 (Goal-Based Agents)
- 목표를 달성하는 동작을 선택한다.
- 세계에 대한 현재 상태 뿐만 아니라 달성하고자 하는 목표도 함께 저장한다.
 목표 기반 에이전트
목표 기반 에이전트
✅ 유틸리티 기반 (Utility-Based Agents)
- 이 환경이 나은지 저 환경이 나은지 비교
- 서로 다른 세계의 상태를 비교하기 위해 조금 더 일반적인 성능 지표를 사용한다. (Utility)
 유틸리티 기반 에이전트
유틸리티 기반 에이전트
전통적인 AI 방법론 (Traditional AI Methods)
✅ 문제 해결 (Problem-Solving)
- 문제 해결은 에이전트의 개수에 따라 탐색과 게임으로 나뉜다.
1️⃣ 탐색 (Search)
- 현재 즉각 어떤 행동을 취해야 할지 확실하지 않은 경우, 단일 에이전트는 미리 계획을 세워야 한다.
- 목표 상태에 도달하기 위한 일련의 동작 고려
- 문제 해결 에이전트
- 이러한 계산 과정들을 일컬어 탐색이라고 한다.
 최단 경로 탐색
최단 경로 탐색
- 문제 해결의 4단계:
- 목표 설정 (Goal Formulation)
- 문제 설정 (Problem Formulation)
- 탐색 (Search)
- 실행 (Execution)
- 탐색 문제는 아래와 같이 정의된다.
- 가능한 상태의 집합
- 초기 상태
- 목표 상태 집합
- 동작
- 트랜지션 모델
- 현재 State와 동작을 input으로 받아서 다음 State를 output으로 내는 함수
- f(s, a) → s
- ex) f(Arad, ↓) == 118
- 동작 비용 함수
- 탐색의 실사용 예시
- 여행문제 (외판원 문제)
- 여러 도시들을 어떻게 가장 적은 시간에 효율적으로 방문할 수 있는가
- VLSI 레이아웃
- 어떻게하면 더 적은 선으로 원하는 목표 회로에 도달할 수 있는가
- 네비게이션
- 자동조립 시퀀싱
- 단백질 설계
2️⃣ 게임 (Game Playing)
- 목표 달성을 위해 여러 에이전트가 협력하거나 경쟁하는 것
- 적대적 탐색 문제: 두 개 이상의 에이전트가 서로 상충하는 목표를 가진 경쟁적 환경
- 다중 에이전트가 존재하는 적대적 환경을 대하는 세 가지 방법:
- 매우 많은 에이전트를 모아 경제를 구성한다.
- 적대적 에이전트들을 환경의 일부로 고려한다.
- 적대적 게임 트리 탐새을 통해 에이전트를 명시적으로 모델링한다.
✅ 표현 (Representation)
- 모든 인공지능 문제들은 일정 표현을 필요로 한다.
- 체스판, 미로, 텍스트, 객체, 장면을 어떻게 표현할 것인가?
- 최적 해를 효율적으로 탐색하도록 문제를 잘 표현하는 것이 인공지능의 주된 분야이다.
- 종종 표현 자체가 출력이 되는 경우도 있다.
✅ 추론 (Reasoning)
- 추론은 세계에 대한 정확한 모델을 만드는 과정으로 볼 수 있다.
1️⃣ 합리적 추론 (Rational Inference)
- 주어진 정보로부터 논리적으로 추론할 수 있는 결과는 무엇인가?
- 단순하고 기계적인 계산
- ex)
raining is true
IF raining is true THEN wet streat is true
wet street is true
2️⃣ 확률적 추론 (Probabilistic Inference)
- 불확실한 정보를 통한 추론: 대부분의 정보는 구체적이지 않고 불확실하다.
- 불확실한 모델, 관측, 지식을 기반으로 추론
- 각 관측에 대해 얼마만큼의 비중을 두어야 할 것인가?
- 방법론:
- 베이지안 네트워크 (Bayes Nets)
- 히든 마르코프 모델 (Hidden Markov Models)
- 동적 베이지안 (Dynamic Bayesian Networks)
- 마르코프 결정 과정 (Markov Decision Process)
✅ 학습 (Learning)
- 만약 세계가 변화한다면?
- 이 경우 인공지능 모델의 정확성을 어떻게 유지할 것인가?
- 학습: 모델 내부 표현을 변화하는 세계에 적응시켜 정확성을 유지한다.
- 방법론:
- 결정 트리 (Decision Trees)
- 신경망 (Neural Network)
- 최근접 이웃 (Nearest Neighbors)
- 강화 학습 (Reinforcement Learning)
![[AI] 인공지능 방법론 - Traditional AI Methods](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbmTx1D%2FbtsGBh7Ujzp%2FXrExlZSI5FzGGOlAK8Qfj1%2Fimg.png)